Slurm HPC Scheduler
Slurm is a highly configurable open-source workload manager. In its simplest configuration, it can be installed and configured in a few minutes. Use of optional plugins provides the functionality needed to satisfy the needs of demanding HPC centers. More complex configurations rely upon a database for archiving accounting records, managing resource limits, and supporting sophisticated scheduling algorithms.
Architecture
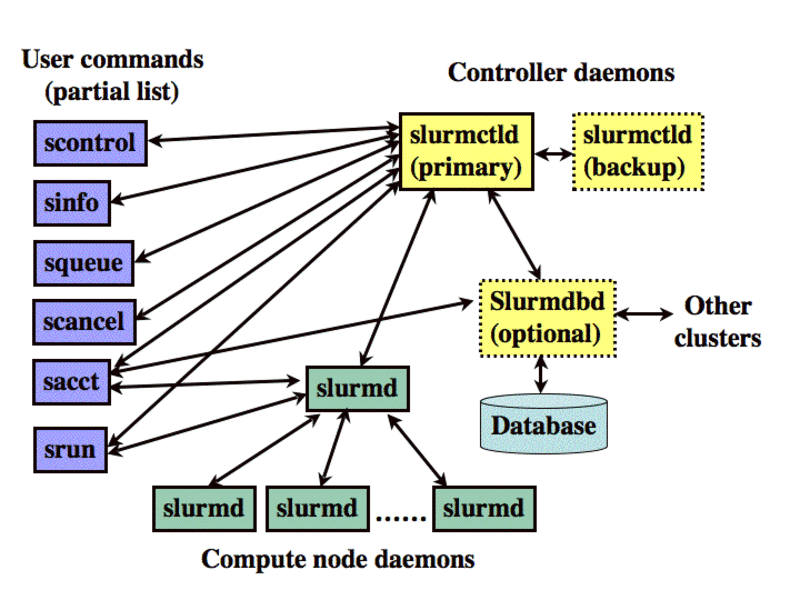
As depicted in the above picture, Slurm consists of a worker daemon (slurmd) running on each compute node and a central controller daemon (slurmctld) running on a management node (with optional fail-over twin). The slurmd daemons provide fault-tolerant hierarchical communications.
Features, Generic consumable Resources and Partitions
Every cluster will have their specific features (–constraint), generic consumable resources (–gres) and partitions.
Submitting Jobs
Before submitting jobs please note the maximum number of jobs and maximum number of job steps per job which can be scheduled. These numbers can be obtained using the scontrol show config command on the headnode.
sbatch is used to submit a job script for later execution. The script will typically contain one task or (if required) multiple srun commands to launch parallel tasks. See the sbatch and srun wiki page for more details.
Interactive Jobs
It is possible to request for an interactive job, within this job you can execute small experiments. Use this only for a short time (max 1 hour). See the srun wiki page for more details.
Monitoring Slurm
To monitor the jobs and progress you can use the corresponding slurm dashboard page or the available command line tools like squeue or scontrol.